This document will introduce you to Singularity, and the links in the bar to the left will give you more detail on using the software. If you want to get a quick rundown, see our quickstart. If you want to understand which commands are best fit for your usecase, see our build flow page. There is also a separate Singularity Administration Guide that targets system administrators, so if you are a service provider, or an interested user, it is encouraged that you read that document as well.
Welcome to Singularity!
Singularity is a container solution created by necessity for scientific and application driven workloads.
Over the past decade and a half, virtualization has gone from an engineering toy to a global infrastructure necessity and the evolution of enabling technologies has flourished. Most recently, we have seen the introduction of the latest spin on virtualization… “containers”. People tend to view containers in light of their virtual machine ancestry and these preconceptions influence feature sets and expected use cases. This is both a good and a bad thing…
For industry and enterprise-centric container technologies this is a good thing. Web enabled cloud requirements are very much in alignment with the feature set of virtual machines, and thus the preceding container technologies. But the idea of containers as miniature virtual machines is a bad thing for the scientific world and specifically the high performance computation (HPC) community. While there are many overlapping requirements in these two fields, they differ in ways that make a shared implementation generally incompatible. Some groups have leveraged custom-built resources that can operate on a lower performance scale, but proper integration is difficult and perhaps impossible with today’s technology.
Many scientists could benefit greatly by using container technology, but they need a feature set that differs somewhat from that available with current container technology. This necessity drives the creation of Singularity and articulated its four primary functions:
Mobility Of Compute
Mobility of compute is defined as the ability to define, create and maintain a workflow and be confident that the workflow can be executed on different hosts, operating systems (as long as it is Linux) and service providers. Being able to contain the entire software stack, from data files to library stack, and portably move it from system to system is true mobility.
Singularity achieves this by utilizing a distributable image format that contains the entire container and stack into a single file. This file can be copied, shared, archived, and standard UNIX file permissions also apply. Additionally containers are portable (even across different C library versions and implementations) which makes sharing and copying an image as easy as cp or scp or ftp.
Reproducibility
As mentioned above, Singularity containers utilize a single file which is the complete representation of all the files within the container. The same features which facilitate mobility also facilitate reproducibility. Once a contained workflow has been defined, the container image can be snapshotted, archived, and locked down such that it can be used later and you can be confident that the code within the container has not changed.
User Freedom
System integrators, administrators, and engineers spend a lot of effort maintaining their systems, and tend to take a cautious approach. As a result, it is common to see hosts installed with production, mission critical operating systems that are “old” and have few installed packages. Users may find software or libraries that are too old or incompatible with the software they must run, or the environment may just lack the software stack they need due to complexities with building, specific software knowledge, incompatibilities or conflicts with other installed programs.
Singularity can give the user the freedom they need to install the applications, versions, and dependencies for their workflows without impacting the system in any way. Users can define their own working environment and literally copy that environment image (single file) to a shared resource, and run their workflow inside that image.
Support On Existing Traditional HPC
Replicating a virtual machine cloud like environment within an existing HPC resource is not a reasonable goal for many administrators. There are a lots of container systems available which are designed for enterprise, as a replacement for virtual machines, are cloud focused, or require unstable or unavailable kernel features.
Singularity supports existing and traditional HPC resources as easily as installing a single package onto the host operating system. Custom configurations may be achieved via a single configuration file, and the defaults are tuned to be generally applicable for shared environments.
Singularity can run on host Linux distributions from RHEL6 (RHEL5 for versions lower than 2.2) and similar vintages, and the contained images have been tested as far back as Linux 2.2 (approximately 14 years old). Singularity natively supports InfiniBand, Lustre, and works seamlessly with all resource managers (e.g. SLURM, Torque, SGE, etc.) because it works like running any other command on the system. It also has built-in support for MPI and for containers that need to leverage GPU resources.
A High Level View of Singularity
Security and privilege escalation
A user inside a Singularity container is the same user as outside the container
This is one of Singularities defining characteristics. It allows a user (that may already have shell access to a particular host) to simply run a command inside of a container image as themselves. Here is a scenario to help articulate this:
%SERVER and %CLUSTER are large expensive systems with resources far exceeding those of my personal workstation. But because the are shared systems, no users have root access. The environments are tightly controlled and managed by a staff of system administrators. To keep these systems secure, only the system administrators are granted root access and they control the state of the operating systems and installed applications. If a user is able to escalate to root (even within a container) on %SERVER or %CLUSTER, they can do bad things to the network, cause denial of service to the host (as well as other hosts on the same network), and may have unrestricted access to file systems reachable by the container.
To mitigate security concerns like this, Singularity limits one’s ability to escalate permission inside a container. For example, if I do not have root access on the target system, I should not be able to escalate my privileges within the container to root either. This is semi-antagonistic to Singularity’s 3rd tenant; allowing the users to have freedom of their own environments. Because if a user has the freedom to create and manipulate their own container environment, surely they know how to escalate their privileges to root within that container. Possible means could be setting the root user’s password, or enabling themselves to have sudo access. For these reasons, Singularity prevents user context escalation within the container, and thus makes it possible to run user supplied containers on shared infrastructures.
This mitigation dictates the Singularity workflow. If a user needs to be root in order to make changes to their containers, then they need to have an endpoint (a local workstation, laptop, or server) where they have root access. Considering almost everybody at least has a laptop, this is not an unreasonable or unmanageable mitigation, but it must be defined and articulated.
The Singularity container image
Singularity makes use of a container image file, which physically contains the container. This file is a physical representation of the container environment itself. If you obtain an interactive shell within a Singularity container, you are literally running within that file.
This simplifies management of files to the element of least surprise, basic file permission. If you either own a container image, or have read access to that container image, you can start a shell inside that image. If you wish to disable or limit access to a shared image, you simply change the permission ACLs to that file.
There are numerous benefits for using a single file image for the entire container:
- Copying or branching an entire container is as simple as
cp - Permission/access to the container is managed via standard file system permissions
- Large scale performance (especially over parallel file systems) is very efficient
- No caching of the image contents to run (especially nice on clusters)
- Containers are compressed and consume very little disk space
- Images can serve as stand-alone programs, and can be executed like any other program on the host
Copying, sharing, branching, and distributing your image
A primary goal of Singularity is mobility. The single file image format makes mobility easy. Because Singularity images are single files, they are easily copied and managed. You can copy the image to create a branch, share the image and distribute the image as easily as copying any other file you control!
If you want an automated solution for building and hosting your image, you can use our container registry Singularity Hub. Singularity Hub can automatically build Singularity recipe files from a GitHub repository each time that you push. It provides a simple cloud solution for storing and sharing your image. If you want to host your own Registry, then you should check out Singularity Registry. If you have ideas or suggestions for how Singularity can better support reproducible science, please reach out!.
Supported container formats
- squashfs: the default container format is a compressed read-only file system that is widely used for things like live CDs/USBs and cell phone OS’s
- ext3: (also called
writable) a writable image file containing an ext3 file system that was the default container format prior to Singularity version 2.4 - directory: (also called
sandbox) standard Unix directory containing a root container image - tar.gz: zlib compressed tar archive
- tar.bz2: bzip2 compressed tar archive
- tar: uncompressed tar archive
Supported URIs
Singularity also supports several different mechanisms for obtaining the images using a standard URI format
- shub:// Singularity Hub is our own registry for Singularity containers. If you want to publish a container, or give easy access to others from their command line, or enable automatic builds, you should build it on Singularity Hub.
- docker:// Singularity can pull Docker images from a Docker registry, and will run them non-persistently (e.g. changes are not persisted as they can not be saved upstream). Note that pulling a Docker image implies assembling layers at runtime, and two subsequent pulls are not guaranteed to produce an identical image.
- instance:// A Singularity container running as service, called an instance, can be referenced with this URI.
Name-spaces and isolation
When asked, “What namespaces does Singularity virtualize?”, the most appropriate response from a Singularity use case is “As few as possible!”. This is because the goals of Singularity are mobility, reproducibility and freedom, not full isolation (as you would expect from industry driven container technologies). Singularity only separates the needed namespaces in order to satisfy our primary goals.
Coupling incomplete isolation with the fact that a user inside a container is the same user outside the container, allows Singularity to blur the lines between a container and the underlying host system. Using Singularity feels like running in a parallel universe, where there are two timelines. In one timeline, the system administrators installed their operating system of choice. But on an alternate timeline, we bribed the system administrators and they installed our favorite operating system and apps, and gave us full control but configured the rest of the system identically. And Singularity gives us the power to pick between these two timelines.
In other words, Singularity allows you to virtually swap out the underlying operating system for one that you’ve defined without affecting anything else on the system and still having all of the host resources available to us.
It’s like ssh’ing into another identical host running a different operating system. One moment you are on Centos-6 and the next minute you are on the latest version of Ubuntu that has Tensorflow installed, or Debian with the latest OpenFoam, or a custom workflow that you installed. But you are still the same user with the same files running the same PIDs.
Additionally, the selection of name-space virtualization can be dynamic or conditional. For example, the PID namespace is not separated from the host by default, but if you want to separate it, you can with a command line (or environment variable) setting. You can also decide you want to contain a process so it can not reach out to the host file system if you don’t know if you trust the image. But by default, you are allowed to interface with all of the resources, devices and network inside the container as you are outside the container.
Compatibility with standard work-flows, pipes and IO
Singularity abstracts the complications of running an application in an environment that differs from the host. For example, applications or scripts within a Singularity container can easily be part of a pipeline that is being executed on the host. Singularity containers can also be executed from a batch script or other program (e.g. an HPC system’s resource manager) natively.
Some usage examples of Singularity can be seen as follows:
$ singularity exec dummy.img xterm # run xterm from within the container
$ singularity exec dummy.img python script.py # run a script on the host system using container's python
$ singularity exec dummy.img python < /path/to/python/script.py # do the same via redirection
$ cat /path/to/python/script.py | singularity exec dummy.img python # do the same via a pipe
You can even run MPI executables within the container as simply as:
$ mpirun -np X singularity exec /path/to/container.img /usr/bin/mpi_program_inside_container (mpi program args)
The Singularity Process Flow
When executing container commands, the Singularity process flow can be generalized as follows:
- Singularity application is invoked
- Global options are parsed and activated
- The Singularity command (subcommand) process is activated
- Subcommand options are parsed
- The appropriate sanity checks are made
- Environment variables are set
- The Singularity Execution binary is called (
sexec) - Sexec determines if it is running privileged and calls the
SUIDcode if necessary - Namespaces are created depending on configuration and process requirements
- The Singularity image is checked, parsed, and mounted in the
CLONE_NEWNSnamespace - Bind mount points are setup so that files on the host are visible in the container
- The namespace
CLONE_FSis used to virtualize a new root file system - Singularity calls
execvp()and Singularity process itself is replaced by the process inside the container - When the process inside the container exits, all namespaces collapse with that process, leaving a clean system
All of the above steps take approximately 15-25 thousandths of a second to run, which is fast enough to seem instantaneous.
The Singularity Usage Workflow
The security model of Singularity (as described above, “A user inside a Singularity container is the same user as outside the container”) defines the Singularity workflow. There are generally two groups of actions you must implement on a container; management (building your container) and usage.
In many circumstances building containers require root administrative privileges just like these actions would require on any system, container, or virtual machine. This means that a user must have access to a system on which they have root privileges. This could be a server, workstation, a laptop, virtual machine, or even a cloud instance. If you are using OS X or Windows on your laptop, it is recommended to setup Vagrant, and run Singularity from there (there are recipes for this which can be found at http://singularity.lbl.gov/). Once you have Singularity installed on your endpoint of choice, this is where you will do the bulk of your container development.
This workflow can be described visually as follows:
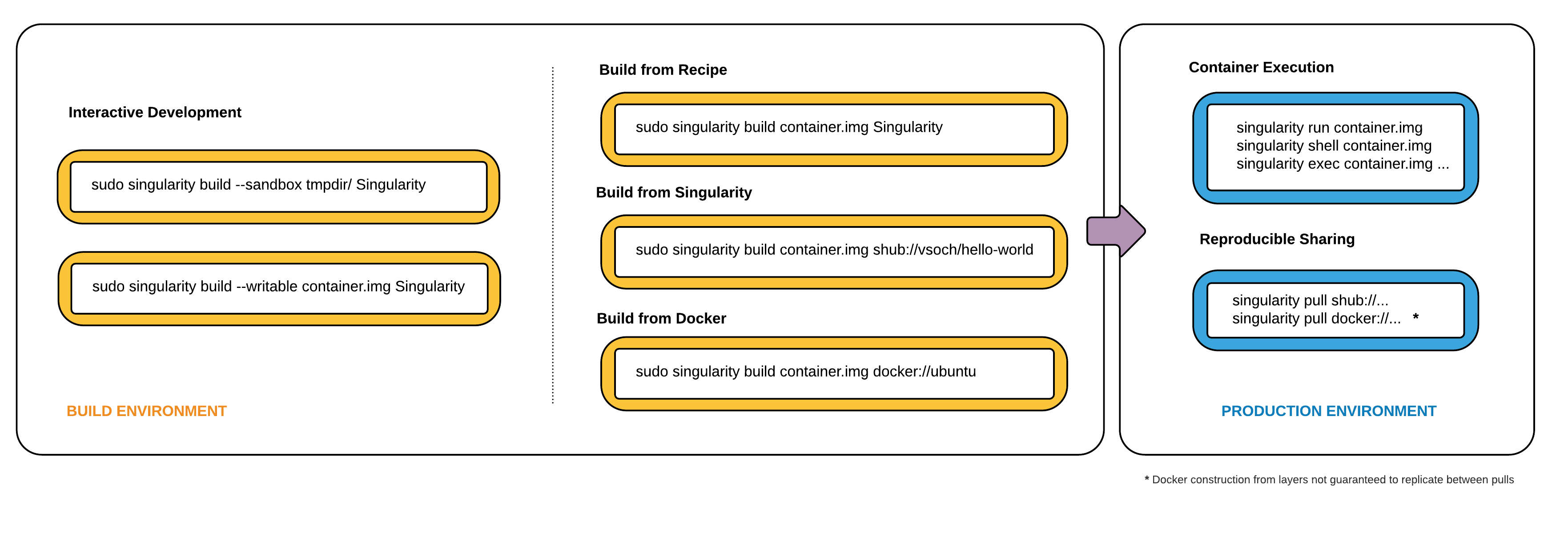
On the left side, you have your build environment: a laptop, workstation, or a server that you control. Here you will (optionally):
- develop and test containers using
--sandbox(build into a writable directory) or--writable(build into a writable ext3 image) - build your production containers with a squashfs filesystem.
Once you have the container with the necessary applications, libraries and data inside it can be easily shared to other hosts and executed without requiring root access. A production container should be an immutable object, so if you need to make changes to your container you should go back to your build system with root privileges, rebuild the container with the necessary changes, and then re-upload the container to the production system where you wish to run it.
Singularity Commands
How do the commands work? Here is where to look for more information:
- build: Build a container on your user endpoint or build environment
- exec: Execute a command to your container
- inspect: See labels, run and test scripts, and environment variables
- pull: pull an image from Docker or Singularity Hub
- run: Run your image as an executable
- shell: Shell into your image
Image Commands
- image.import: import layers or other file content to your image
- image.export: export the contents of the image to tar or stream
- image.create: create a new image, using the old ext3 filesystem
- image.expand: increase the size of your image (old ext3)
Instance Commands
Instances were added in 2.4. This list is brief, and likely to expand with further development.
- instances: Start, stop, and list container instances
Deprecated Commands The following commands are deprecated in 2.4 and will be removed in future releases.
- bootstrap: Bootstrap a container recipe
Support
Have a question, or need further information? Reach out to us.